Inside a Real Enterprise RAG Architecture
Category: Architecture Publish Order: 2/5
---
Most RAG content on the internet is written like enterprise retrieval is just embeddings plus a vector database.
That is not how enterprise retrieval works.
Real enterprise environments contain source code, internal docs, policies, tickets, spreadsheets, and structured systems. Some queries need exact precision. Some need keyword relevance. Some need semantic similarity. Treating all of them as vector search is how you get noisy retrieval, weak provenance, and bad answers wrapped in confident language.
Enterprise RAG Is Not One Retrieval Strategy
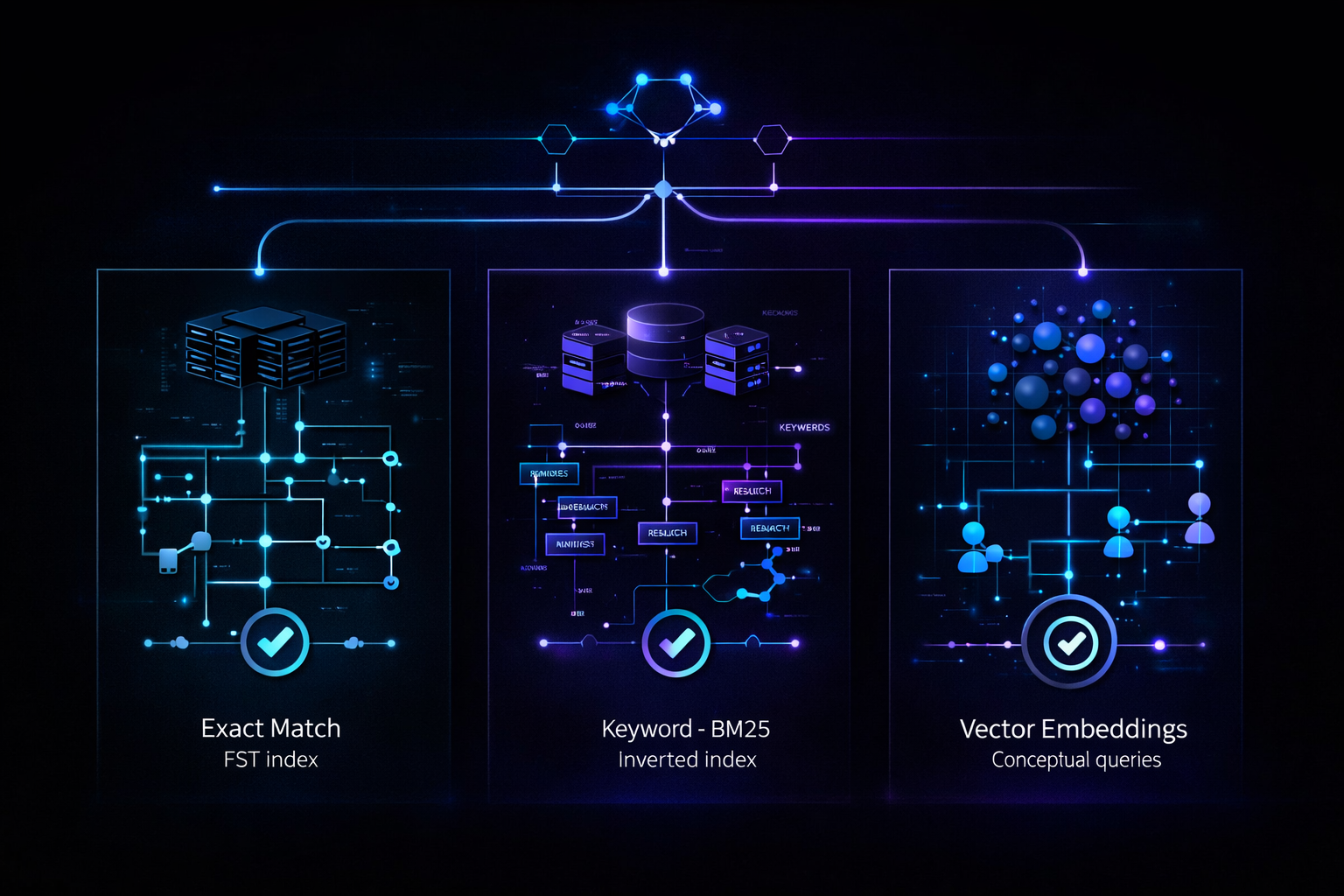
A real enterprise RAG system needs multiple retrieval strategies and a routing layer that chooses the right one for the query.
At Srasta, the architecture is closer to this:
1. Exact Match Retrieval
If a user asks for a specific function, path, identifier, policy code, or known asset, semantic retrieval is the wrong tool.
Exact-match indexes are faster and more reliable for high-precision lookups.
results = exact_match_index.lookup(path="/billing/api.py", symbol="process_payment")This matters because enterprise users often ask for exact things, not just conceptual similarity.
2. Keyword and BM25 Retrieval
A large class of enterprise questions are still best answered with keyword retrieval.
If a user asks for authentication logic, access policies, deployment workflows, or references to a named system, terminology matters. BM25 and inverted indexing preserve that structure better than forcing everything through embeddings.
results = keyword_index.search("authentication", "user", "login")This matters because enterprise terminology is not generic web language. Internal naming conventions and domain-specific vocabulary are often the signal.
3. Vector Retrieval
Vector search still matters, but it should be used where it actually helps: conceptual discovery, related content, or similarity-based retrieval.
results = vector_index.similarity(billing_module_embedding)This matters because semantic retrieval is useful when the question is exploratory, not exact.
The Router Is the Real Architecture
The most important part of enterprise RAG is not any single retrieval method. It is the decision layer that routes the query correctly.
def route(query):
if query.is_exact_path():
return EXACT
if query.has_keywords():
return KEYWORD
return VECTORThat routing layer is where enterprise RAG becomes usable.
Without it, every question gets pushed through the same retrieval path, and the system starts returning answers that are technically plausible but operationally wrong.
Why This Matters in Enterprise Environments
A public chatbot can survive fuzzy retrieval. Enterprise systems cannot.
If retrieval is wrong in an enterprise setting, the consequences are larger:
- Developers get the wrong code context
- Security teams get incomplete policy references
- Internal knowledge systems return low-trust answers
- Auditability suffers because provenance is weak or mixed
In enterprise RAG, precision is not a nice-to-have. It is the reason the architecture exists.
Retrieval Alone Is Still Not Enough
A real enterprise RAG stack also needs:
- access-aware retrieval boundaries
- provenance on returned content
- audit logs for retrieval and answer generation
- deployment patterns that work in private-cloud or on-prem environments
Otherwise it is still just generic retrieval pointed at private data.
Final Point
The mistake most teams make is assuming enterprise RAG is a vector database problem.
It is not.
It is a routing, governance, provenance, and retrieval-discipline problem. That is why generic RAG demos collapse when they meet enterprise data, enterprise permissions, and enterprise expectations.
---